I recently came across a very interesting paper by Y. Yu and X. Meng[1] who present an interweaving strategy between different model parameterizations to improve mixing. It is well known that different model parameterizations can perform better than others under certain conditions. Papaspiliopoulos, Roberts and Sköld [2] present a general framework for how to parameterize hierarchical models and provide insights into the conditions under which centered and non-centered parameterizations outperform each other. One isn’t, however, restricted to reperameterizations of location parameters only, as outlined in the aforementioned paper, and so I decided to experiment with reparameterizations of the scale parameter in a simple hierarchical model with improper priors on the parameters.
Centered Parameterization
Papaspiliopoulos gave a general definition of the centered parameterization to be when 


 \ \ \ \ \ (1)")
 \ \ \ \ \ (2)")
 \propto \frac{1}{\lambda^{2}} \ \ \ \ \ (3)")
Full Conditionals
 \ \ \ \ \ (4)")
 \ \ \ \ \ (5)")
Non-Centered Parameterization
Papaspiliopoulos gave a general definition of the non-centered parameterization to be when 
 \ \ \ \ \ (6)")
 \ \ \ \ \ (7)")
 \propto 1 \ \ \ \ \ (8)")
Full Conditionals
 \ \ \ \ \ (9)")
 \ \ \ \ \ (10)")
Interweaving Strategy
Generally when the CP works well, the NCP works poorly and vice versa. Yaming Yu and Xiao-Li Meng[1] present a way of combining both strategies by interweaving the Gibbs steps of both parameterizations at each iteration. The details can be read in their paper. I decided to test all three Gibbs samplers with the following R code:
#Generate Data
lam2=0.5
lam=sqrt(lam2)
sig2=1
n=1000
Xt=rnorm(n,0,sqrt(lam2*sig2))
Y=rnorm(n,Xt,sqrt(sig2))
nmc=2000
X=Xt
#Centered Parameterization
cp_lam2=rep(0,nmc)
cp_X=matrix(0,nmc,n)
for(i in 1:nmc){
inv_lam2=rgamma(1,(n)/2,rate=(t(X)%*%X)/(2*sig2))
lam2=1/inv_lam2
X=rnorm(n,(1/(1/sig2 + 1/(sig2*lam2)))*Y/sig2, sqrt(1/(1/sig2 + 1/(sig2*lam2))))
cp_lam2[i]=lam2
cp_X[i,]=X
}
mean_cp_X=apply(cp_X,2,mean)
#Non-Centered Parameterization
X=Xt
ncp_lam2=rep(0,nmc)
ncp_X=matrix(0,nmc,n)
for(i in 1:nmc){
lam=rnorm(1,t(X)%*%Y/(t(X)%*%X), sqrt(sig2/(t(X)%*%X)))
lam2=lam*lam;
X=rnorm(n, (1/(1/sig2 + lam2/sig2))*lam*Y/sig2, sqrt(1/(1/sig2+lam2/sig2)) )
ncp_lam2[i]=lam2
ncp_X[i,]=X
}
mean_ncp_X=apply(ncp_X,2,mean)
#Interweaving Strategy
int_lam2=rep(0,nmc)
int_X=matrix(0,nmc,n)
for(i in 1:nmc){
X=rnorm(n,(1/(1/sig2 + 1/(sig2*lam2)))*Y/sig2, sqrt(1/(1/sig2 + 1/(sig2*lam2))))
inv_lam2=rgamma(1,(n)/2,rate=(t(X)%*%X)/(2*sig2))
half_lam2=1/inv_lam2
X=X/sqrt(half_lam2) #Transform to Xtilde
lam=rnorm(1,t(X)%*%Y/(t(X)%*%X), sqrt(sig2/(t(X)%*%X)))
lam2=lam*lam;
int_lam2[i]=lam2
int_X[i,]=X
}
mean_cp_X=apply(cp_X,2,mean)
#Remove Burnin
cp_lam2=cp_lam2[-(1:1000)]
ncp_lam2=ncp_lam2[-(1:1000)]
int_lam2=int_lam2[-(1:1000)]
#Plot Results
par(mfrow=c(3,3))
acf(cp_lam2)
plot(cp_lam2,type="l")
plot(cp_lam2[1:nmc-1],cp_lam2[2:nmc])
acf(ncp_lam2)
plot(ncp_lam2,type="l")
plot(ncp_lam2[1:nmc-1],ncp_lam2[2:nmc])
acf(int_lam2)
plot(int_lam2,type="l")
plot(int_lam2[1:nmc-1],int_lam2[2:nmc])
Results

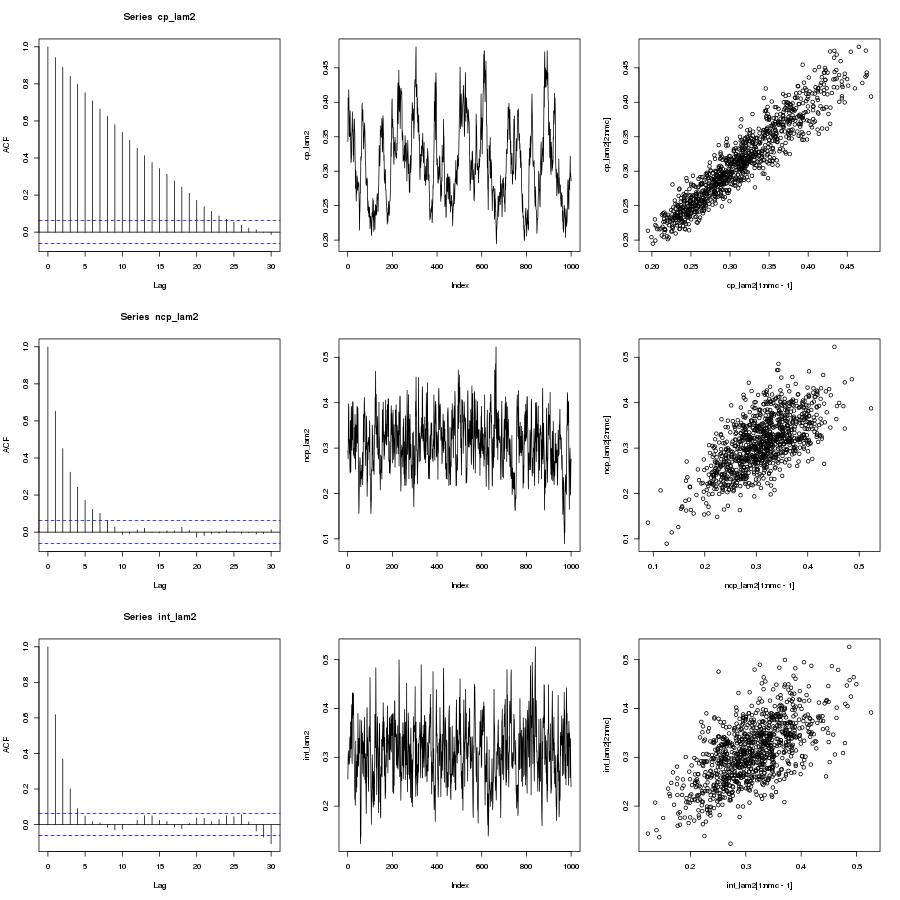
Interweaving outperforms non-centered outperforms centered

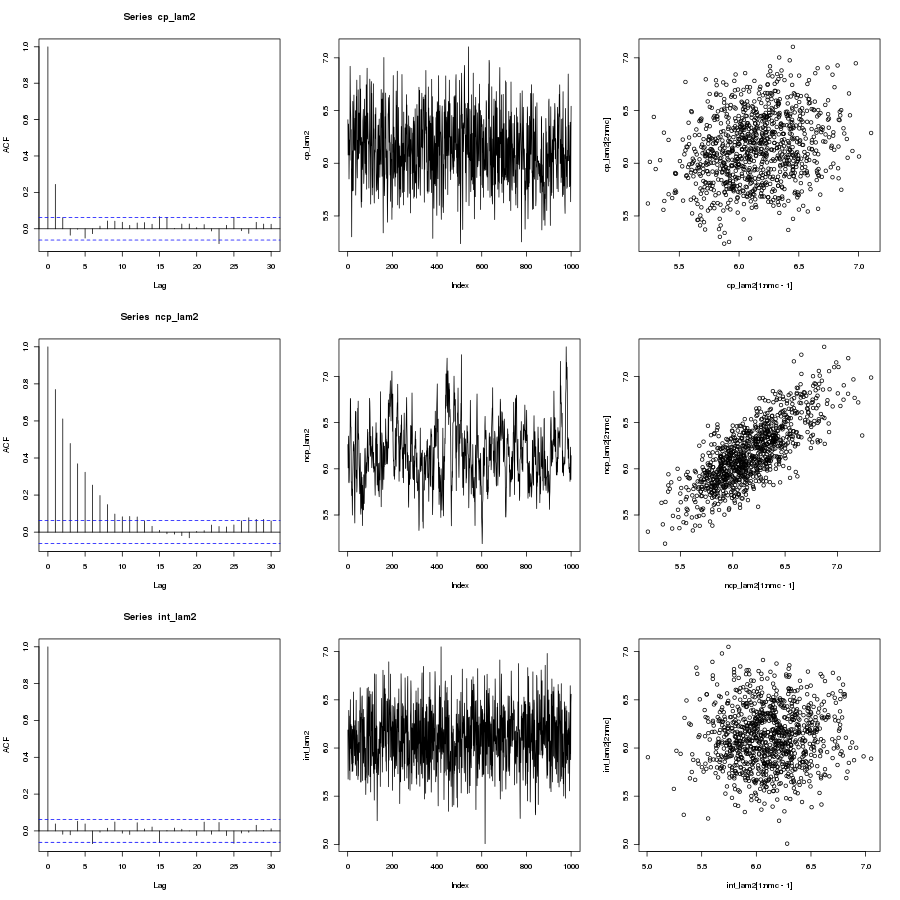
Interweaving outperforms centered outperforms non-centered
Discussion
As lambda gets small the centered parameterization becomes ever more autocorrelated and poorly mixing. When lambda becomes large the non-centered parameterization becomes ever more autocorrelated and poorly mixing. The interweaved Gibbs sampler exhibits great mixing in all cases.
[Bibtex]
@article{Yu11,
author = {Yu, Yaming and Meng, Xiao-Li},
citeulike-article-id = {10408757},
citeulike-linkout-0 = {http://amstat.tandfonline.com/doi/abs/10.1198/jcgs.2011.203main},
citeulike-linkout-1 = {http://pubs.amstat.org/doi/abs/10.1198/jcgs.2011.203main},
citeulike-linkout-2 = {http://dx.doi.org/10.1198/jcgs.2011.203main},
doi = {10.1198/jcgs.2011.203main},
journal = {Journal of Computational and Graphical Statistics},
number = {3},
pages = {531--570},
posted-at = {2012-03-03 18:10:07},
priority = {2},
title = {{To Center or Not to Center: That Is Not the Question--An Ancillarity-Sufficiency Interweaving Strategy (ASIS) for Boosting MCMC Efficiency}},
url = {http://amstat.tandfonline.com/doi/abs/10.1198/jcgs.2011.203main},
volume = {20},
year = {2011}
}[Bibtex]
@article{Papaspiliopoulos07,
abstract = {{In this paper, we describe centering and noncentering methodology as complementary techniques for use in parametrization of broad classes of hierarchical models, with a view to the construction of effective MCMC algorithms for exploring posterior distributions from these models. We give a clear qualitative understanding as to when centering and noncentering work well, and introduce theory concerning the convergence time complexity of Gibbs samplers using centered and noncentered parametrizations. We give general recipes for the construction of noncentered parametrizations, including an auxiliary variable technique called the state-space expansion technique. We also describe partially noncentered methods, and demonstrate their use in constructing robust Gibbs sampler algorithms whose convergence properties are not overly sensitive to the data.}},
author = {Papaspiliopoulos, Omiros and Roberts, Gareth O. and Sk\"{o}ld, Martin},
citeulike-article-id = {8977350},
citeulike-linkout-0 = {http://www.jstor.org/stable/27645805},
journal = {Statistical Science},
number = {1},
pages = {59--73},
posted-at = {2011-03-10 18:55:50},
priority = {2},
publisher = {Institute of Mathematical Statistics},
title = {{A general framework for the parametrization of hierarchical models}},
url = {http://www.jstor.org/stable/27645805},
volume = {22},
year = {2007}
}Yu Y. & Meng X.L. (2011). To Center or Not to Center: That Is Not the Question—An Ancillarity–Sufficiency Interweaving Strategy (ASIS) for Boosting MCMC Efficiency, Journal of Computational and Graphical Statistics, 20 (3) 531-570. DOI: 10.1198/jcgs.2011.203main
 one can obtain
one can obtain  by using the Woodbury matrix identity and vice versa. Recall the
by using the Woodbury matrix identity and vice versa. Recall the 

 , then the variance of the conditional distribution
, then the variance of the conditional distribution  is the Schur complement of the block
is the Schur complement of the block  of total variance matrix
of total variance matrix  , that is, the variance of the conditional distribution is
, that is, the variance of the conditional distribution is  which is the variance of
which is the variance of  subtracted by something corresponding to the reduction in uncertainty about
subtracted by something corresponding to the reduction in uncertainty about  . If, however,
. If, however, 
")
")
 and arrived there through two different paths. The distributions derived looked very different, but they turned out to be equivalent upon considering the Woodbury identity.
and arrived there through two different paths. The distributions derived looked very different, but they turned out to be equivalent upon considering the Woodbury identity. one gets
one gets \begin{bmatrix} X_{1}^{T} & X_{2}^{T} \end{bmatrix} + Cov(\varepsilon)")

 \right)")
![Y_{1}| Y_{2} ,\sigma^{2} \sim N \left( X_{1}\Lambda^{-1} X_{2}^{T} \left[ X_{2}\Lambda^{-1} X_{2}^{T} + I_{2}\right]^{-1} Y_{2}, I_{1} + X_{1}\Lambda^{-1} X_{1}^{T} - X_{1}\Lambda^{-1} X_{2}^{T} \left[ I_{2} + X_{2}\Lambda^{-1} X_{2}^{T} \right]^{-1} X_{2}\Lambda^{-1} X_{1}^{T}\right).](http://s0.wp.com/latex.php?latex=Y_%7B1%7D%7C+Y_%7B2%7D+%2C%5Csigma%5E%7B2%7D+%5Csim+N+%5Cleft%28++X_%7B1%7D%5CLambda%5E%7B-1%7D+X_%7B2%7D%5E%7BT%7D+%5Cleft%5B++X_%7B2%7D%5CLambda%5E%7B-1%7D+X_%7B2%7D%5E%7BT%7D+%2B+I_%7B2%7D%5Cright%5D%5E%7B-1%7D+Y_%7B2%7D%2C+I_%7B1%7D+%2B++X_%7B1%7D%5CLambda%5E%7B-1%7D+X_%7B1%7D%5E%7BT%7D+-++X_%7B1%7D%5CLambda%5E%7B-1%7D+X_%7B2%7D%5E%7BT%7D+%5Cleft%5B+I_%7B2%7D+%2B++X_%7B2%7D%5CLambda%5E%7B-1%7D+X_%7B2%7D%5E%7BT%7D+%5Cright%5D%5E%7B-1%7D++X_%7B2%7D%5CLambda%5E%7B-1%7D+X_%7B1%7D%5E%7BT%7D%5Cright%29.++&bg=ffffff&fg=000&s=0 "Y_{1}| Y_{2} ,\sigma^{2} \sim N \left( X_{1}\Lambda^{-1} X_{2}^{T} \left[ X_{2}\Lambda^{-1} X_{2}^{T} + I_{2}\right]^{-1} Y_{2}, I_{1} + X_{1}\Lambda^{-1} X_{1}^{T} - X_{1}\Lambda^{-1} X_{2}^{T} \left[ I_{2} + X_{2}\Lambda^{-1} X_{2}^{T} \right]^{-1} X_{2}\Lambda^{-1} X_{1}^{T}\right).")
 looks like it too could be a Schur complement of some matrix.
looks like it too could be a Schur complement of some matrix.=\int f( Y_{1}|\sigma^{2} ,\beta_{ })\pi(\beta_{ }| Y_{2},\sigma^{2} )d\beta_{ }")
^{-1} X_{2}^{T} Y_{2}, \sigma^{2}( X_{2}^{T} X_{2}+\Lambda)^{-1} \right).")
^{-1} X_{2}^{T} Y_{2}, \sigma^{2} (I_{1} + X_{1} ( X_{2}^{T} X_{2}+\Lambda)^{-1} X_{1}^{T}) \right)")
![\left[\Lambda+ X_{2}^TI_{2} X_{2}\right]^{-1} X_{2}^T\\ =\{\Lambda^{-1}-\Lambda^{-1} X_{2}^T\left[I_{2}+ X_{2}\Lambda^{-1} X_{2}^T\right]^{-1} X_{2}\Lambda^{-1}\} X_{2}^T\\ =\Lambda^{-1} X_{2}^T\left[I_{2}+ X_{2}\Lambda^{-1} X_{2}^T\right]^{-1}\left[I_{2}+ X_{2}\Lambda^{-1} X_{2}^T\right]-\Lambda^{-1} X_{2}^T\left[I_{2}+ X_{2}\Lambda^{-1} X_{2}^T\right]^{-1} X_{2}\Lambda^{-1} X_{2}^T\\ =\Lambda^{-1} X_{2}^T\left[I_{2}+ X_{2}\Lambda^{-1} X_{2}^T\right]^{-1}I_{2}](http://s0.wp.com/latex.php?latex=%5Cleft%5B%5CLambda%2B++X_%7B2%7D%5ETI_%7B2%7D+X_%7B2%7D%5Cright%5D%5E%7B-1%7D+X_%7B2%7D%5ET%5C%5C++%3D%5C%7B%5CLambda%5E%7B-1%7D-%5CLambda%5E%7B-1%7D+X_%7B2%7D%5ET%5Cleft%5BI_%7B2%7D%2B++X_%7B2%7D%5CLambda%5E%7B-1%7D+X_%7B2%7D%5ET%5Cright%5D%5E%7B-1%7D+X_%7B2%7D%5CLambda%5E%7B-1%7D%5C%7D+X_%7B2%7D%5ET%5C%5C++%3D%5CLambda%5E%7B-1%7D+X_%7B2%7D%5ET%5Cleft%5BI_%7B2%7D%2B++X_%7B2%7D%5CLambda%5E%7B-1%7D+X_%7B2%7D%5ET%5Cright%5D%5E%7B-1%7D%5Cleft%5BI_%7B2%7D%2B++X_%7B2%7D%5CLambda%5E%7B-1%7D+X_%7B2%7D%5ET%5Cright%5D-%5CLambda%5E%7B-1%7D+X_%7B2%7D%5ET%5Cleft%5BI_%7B2%7D%2B++X_%7B2%7D%5CLambda%5E%7B-1%7D+X_%7B2%7D%5ET%5Cright%5D%5E%7B-1%7D+X_%7B2%7D%5CLambda%5E%7B-1%7D+X_%7B2%7D%5ET%5C%5C++%3D%5CLambda%5E%7B-1%7D+X_%7B2%7D%5ET%5Cleft%5BI_%7B2%7D%2B++X_%7B2%7D%5CLambda%5E%7B-1%7D+X_%7B2%7D%5ET%5Cright%5D%5E%7B-1%7DI_%7B2%7D&bg=ffffff&fg=000&s=0 "\left[\Lambda+ X_{2}^TI_{2} X_{2}\right]^{-1} X_{2}^T\\ =\{\Lambda^{-1}-\Lambda^{-1} X_{2}^T\left[I_{2}+ X_{2}\Lambda^{-1} X_{2}^T\right]^{-1} X_{2}\Lambda^{-1}\} X_{2}^T\\ =\Lambda^{-1} X_{2}^T\left[I_{2}+ X_{2}\Lambda^{-1} X_{2}^T\right]^{-1}\left[I_{2}+ X_{2}\Lambda^{-1} X_{2}^T\right]-\Lambda^{-1} X_{2}^T\left[I_{2}+ X_{2}\Lambda^{-1} X_{2}^T\right]^{-1} X_{2}\Lambda^{-1} X_{2}^T\\ =\Lambda^{-1} X_{2}^T\left[I_{2}+ X_{2}\Lambda^{-1} X_{2}^T\right]^{-1}I_{2}")
![\Lambda^{-1} - \Lambda^{-1} X_{2}^{T} \left[ I_{2} + X_{2}\Lambda^{-1} X_{2}^{T} \right]^{-1} X_{2}\Lambda^{-1} = ( X_{2}^{T}I_{2} X_{2}+\Lambda)^{-1}.](http://s0.wp.com/latex.php?latex=%5CLambda%5E%7B-1%7D+-+%5CLambda%5E%7B-1%7D+X_%7B2%7D%5E%7BT%7D+%5Cleft%5B+I_%7B2%7D+%2B++X_%7B2%7D%5CLambda%5E%7B-1%7D+X_%7B2%7D%5E%7BT%7D+%5Cright%5D%5E%7B-1%7D++X_%7B2%7D%5CLambda%5E%7B-1%7D+%3D+%28+X_%7B2%7D%5E%7BT%7DI_%7B2%7D+X_%7B2%7D%2B%5CLambda%29%5E%7B-1%7D.++&bg=ffffff&fg=000&s=0 "\Lambda^{-1} - \Lambda^{-1} X_{2}^{T} \left[ I_{2} + X_{2}\Lambda^{-1} X_{2}^{T} \right]^{-1} X_{2}\Lambda^{-1} = ( X_{2}^{T}I_{2} X_{2}+\Lambda)^{-1}.")
![X_{1}\Lambda^{-1} X_{1}^{T}- X_{1}\Lambda^{-1} X_{2}^{T} \left[ I_{2}+ X_{2}\Lambda^{-1} X_{2}^{T} \right]^{-1} X_{2}\Lambda^{-1} X_{1}^{T}={ X_{1} ( X_{2}^{T} X_{2}+\Lambda)^{-1} X_{1}^{T}}\\](http://s0.wp.com/latex.php?latex=X_%7B1%7D%5CLambda%5E%7B-1%7D+X_%7B1%7D%5E%7BT%7D-+X_%7B1%7D%5CLambda%5E%7B-1%7D+X_%7B2%7D%5E%7BT%7D+%5Cleft%5B+I_%7B2%7D%2B+X_%7B2%7D%5CLambda%5E%7B-1%7D+X_%7B2%7D%5E%7BT%7D+%5Cright%5D%5E%7B-1%7D++X_%7B2%7D%5CLambda%5E%7B-1%7D+X_%7B1%7D%5E%7BT%7D%3D%7B+X_%7B1%7D+%28+X_%7B2%7D%5E%7BT%7D+X_%7B2%7D%2B%5CLambda%29%5E%7B-1%7D+X_%7B1%7D%5E%7BT%7D%7D%5C%5C++&bg=ffffff&fg=000&s=0 "X_{1}\Lambda^{-1} X_{1}^{T}- X_{1}\Lambda^{-1} X_{2}^{T} \left[ I_{2}+ X_{2}\Lambda^{-1} X_{2}^{T} \right]^{-1} X_{2}\Lambda^{-1} X_{1}^{T}={ X_{1} ( X_{2}^{T} X_{2}+\Lambda)^{-1} X_{1}^{T}}\\")
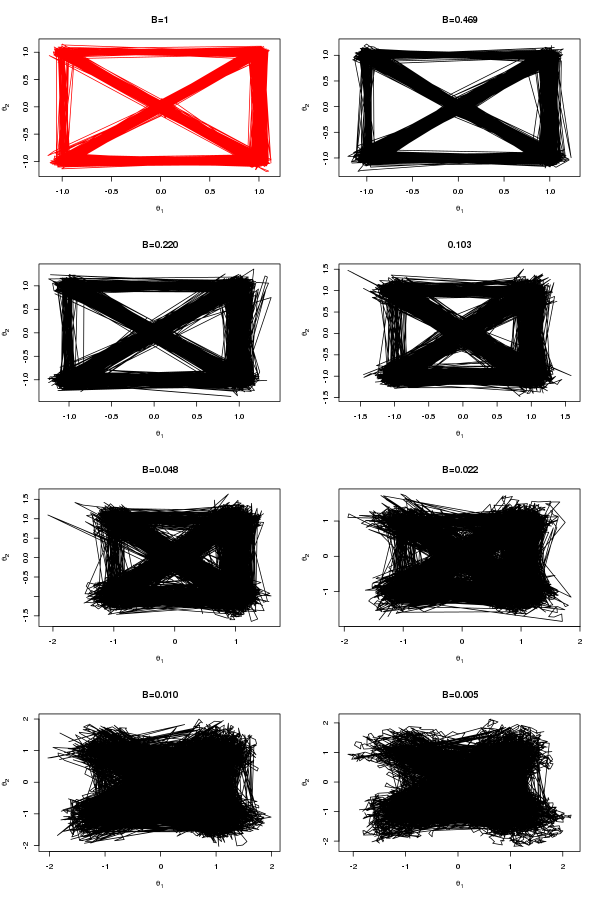
} { p_{j}(\theta_{j} ) } \frac{ p_{j+1} (\theta_{j} )} { p_{j+1}(\theta_{j+1} ) } )")
^{B_{j}}\\ p_{j+1}=\pi(\theta|Y)^{B_{j+1}}")
![log \left( \frac{ p_{j} (\theta_{j+1} )} { p_{j}(\theta_{j} ) } \frac{ p_{j+1} (\theta_{j} )} { p_{j+1}(\theta_{j+1} ) } \right) = (B_{j}-B_{j+1}) \left( log(\pi[\theta_{j+1}|Y]) - log(\pi[\theta_{j}|Y]) \right)](http://s0.wp.com/latex.php?latex=log+%5Cleft%28+%5Cfrac%7B++p_%7Bj%7D+%28%5Ctheta_%7Bj%2B1%7D+%29%7D++%7B+++p_%7Bj%7D%28%5Ctheta_%7Bj%7D+%29+%7D++%5Cfrac%7B++p_%7Bj%2B1%7D+%28%5Ctheta_%7Bj%7D+%29%7D++%7B+++p_%7Bj%2B1%7D%28%5Ctheta_%7Bj%2B1%7D+%29+%7D++++%5Cright%29+%3D++%28B_%7Bj%7D-B_%7Bj%2B1%7D%29+%5Cleft%28+log%28%5Cpi%5B%5Ctheta_%7Bj%2B1%7D%7CY%5D%29+-+log%28%5Cpi%5B%5Ctheta_%7Bj%7D%7CY%5D%29+%5Cright%29++&bg=ffffff&fg=000&s=0 "log \left( \frac{ p_{j} (\theta_{j+1} )} { p_{j}(\theta_{j} ) } \frac{ p_{j+1} (\theta_{j} )} { p_{j+1}(\theta_{j+1} ) } \right) = (B_{j}-B_{j+1}) \left( log(\pi[\theta_{j+1}|Y]) - log(\pi[\theta_{j}|Y]) \right)")
![E_{j}=-log(\pi[\theta_{j}|Y]).](http://s0.wp.com/latex.php?latex=E_%7Bj%7D%3D-log%28%5Cpi%5B%5Ctheta_%7Bj%7D%7CY%5D%29.&bg=ffffff&fg=000&s=0 "E_{j}=-log(\pi[\theta_{j}|Y]).")
(E_{j+1} - E_{j}) }).")
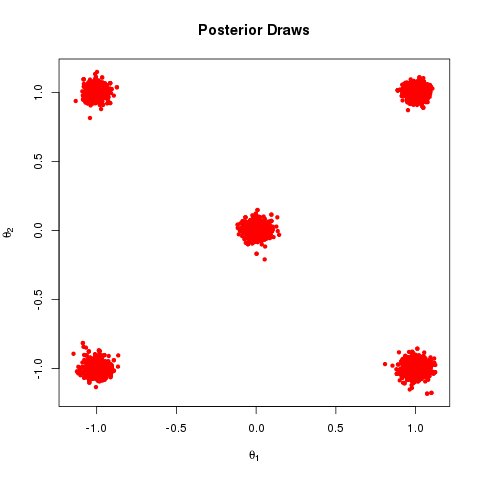
=\pi(\beta|\sigma^{2})\pi(\sigma^{2})\\ \pi(\beta|\sigma^{2})=N(\mu_{0},\sigma^{2} \Lambda_{0}^{-1})\\ \pi(\sigma^{2})=IG(a_{0},b_{0})\\ f(Y|\beta,\sigma^{2})=N(X\beta,\sigma^{2})\\")
\pi(\beta|\sigma^{2})\pi(\sigma^{2})= \left( \frac{1}{2\pi} \right)^{\frac{n}{2}} \left( \frac{1}{\sigma^{2}}\right)^{\frac{n}{2}} e^{-\frac{1}{2\sigma^{2}}(Y-X\beta)'(Y-X\beta)} \left( \frac{1}{2\pi}\right) ^{\frac{k}{2}}\left( \frac{1}{\sigma^{2}} \right)^{\frac{k}{2}} |\Lambda_{0}|^{\frac{1}{2}} e^{-\frac{1}{2\sigma^{2}}(\beta-\mu_{0})'\Lambda_{0}(\beta-\mu_{0})} \frac{b_{0}^{a_{0}}}{\Gamma(a_{0})}\left(\frac{1}{\sigma^{2}}\right)^{a_{0}-1}e^{-\frac{b_{0}}{\sigma^{2}}}\\")
'(Y-X\beta)+(\beta-\mu_{0})\Lambda_{0}(\beta_{0}-\mu_{0})=\\ \beta'(X'X+\Lambda_{0})\beta-2\beta'(X'X\hat{\beta}+\Lambda_{0}\mu_{0}) +\mu_{0}'\Lambda_{0}\mu_{0}+\hat{\beta}X'X\hat{\beta}+Y'(I-P)Y=\\ \beta'(X'X+\Lambda_{0})\beta-2\beta'(X'X\hat{\beta}+\Lambda_{0}\mu_{0}) +\mu_{0}'\Lambda_{0}\mu_{0}+Y'Y")
^{-1}(X'X\hat{\beta}+\Lambda_{0}\mu_{0})=\Lambda_{n}^{-1}(X'X\hat{\beta}+\Lambda_{0}\mu_{0})")
'(Y-X\beta)+(\beta-\mu_{0})\Lambda_{0}(\beta_{0}-\mu_{0})=\\ \beta'\Lambda_{n}\beta-2\beta'\Lambda_{n}\mu_{n}+\mu_{0}'\Lambda_{0}\mu_{0}+Y'Y=\\ (\beta-\mu_{n})\Lambda_{n}(\beta-\mu_{n})-\mu_{n}\Lambda_{n}\mu_{n}+\mu_{0}'\Lambda_{0}\mu_{0}+Y'Y\\")
\pi(\beta|\sigma^{2})\pi(\sigma^{2})=f(Y,\beta,\sigma^{2})=\\ \left( \frac{1}{2\pi} \right)^{\frac{n}{2}} \left( \frac{1}{\sigma^{2}}\right)^{\frac{n}{2}} e^{-\frac{1}{2\sigma^{2}}(Y'Y-\mu_{n}\Lambda_{n}\mu_{n}+\mu_{0}'\Lambda_{0}\mu_{0})} \left( \frac{1}{2\pi}\right) ^{\frac{k}{2}}\left( \frac{1}{\sigma^{2}} \right)^{\frac{k}{2}} |\Lambda_{0}|^{\frac{1}{2}} e^{-\frac{1}{2\sigma^{2}}(\beta-\mu_{n})\Lambda_{n}(\beta-\mu_{n})} \frac{b_{0}^{a_{0}}}{\Gamma(a_{0})}\left(\frac{1}{\sigma^{2}}\right)^{a_{0}-1}e^{-\frac{b_{0}}{\sigma^{2}}}\\")
= \left( \frac{1}{2\pi} \right)^{\frac{n}{2}} \left( \frac{1}{\sigma^{2}}\right)^{\frac{n}{2}} e^{-\frac{1}{2\sigma^{2}}(Y'Y-\mu_{n}\Lambda_{n}\mu_{n}+\mu_{0}'\Lambda_{0}\mu_{0})} \frac{|\Lambda_{0}|^{\frac{1}{2}}}{|\Lambda_{n}|^{\frac{1}{2}}} \frac{b_{0}^{a_{0}}}{\Gamma(a_{0})}\left(\frac{1}{\sigma^{2}}\right)^{a_{0}-1}e^{-\frac{b_{0}}{\sigma^{2}}}\\")
=\left( \frac{1}{2\pi} \right)^{\frac{n}{2}} \left( \frac{1}{\sigma^{2}}\right)^{\frac{n}{2}+a_{0}-1} e^{-\frac{b_{0}+\frac{1}{2}(Y'Y-\mu_{n}'\Lambda_{n}\mu_{n}+\mu_{0}'\Lambda_{0}\mu_{0})}{\sigma^{2}}} \frac{|\Lambda_{0}|^{\frac{1}{2}}}{|\Lambda_{n}|^{\frac{1}{2}}} \frac{b_{0}^{a_{0}}}{\Gamma(a_{0})}")
")
=\left( \frac{1}{2\pi} \right)^{\frac{n}{2}} \frac{|\Lambda_{0}|^{\frac{1}{2}}}{|\Lambda_{n}|^{\frac{1}{2}}} \frac{b_{0}^{a_{0}}}{\Gamma(a_{0})} \left( \frac{1}{\sigma^{2}}\right)^{a_{n}-1} e^{-\frac{b_{n}}{\sigma^{2}}}\\")
=\left( \frac{1}{2\pi} \right)^{\frac{n}{2}} \frac{|\Lambda_{0}|^{\frac{1}{2}}}{|\Lambda_{n}|^{\frac{1}{2}}} \frac{b_{0}^{a_{0}}}{b_{n}^{a_{n}}} \frac{\Gamma(a_{n})}{\Gamma(a_{0})}\\")
![f_{t} \sim N(b_{1} + a\text{sin}(\omega t)- b_{2}1_{ \left[ \tau_{1},\tau_{2} \right] }(t), \sigma^{2})](http://s0.wp.com/latex.php?latex=f_%7Bt%7D+%5Csim+N%28b_%7B1%7D+%2B+a%5Ctext%7Bsin%7D%28%5Comega+t%29-+b_%7B2%7D1_%7B+%5Cleft%5B+%5Ctau_%7B1%7D%2C%5Ctau_%7B2%7D+%5Cright%5D+%7D%28t%29%2C+%5Csigma%5E%7B2%7D%29++&bg=ffffff&fg=000&s=0 "f_{t} \sim N(b_{1} + a\text{sin}(\omega t)- b_{2}1_{ \left[ \tau_{1},\tau_{2} \right] }(t), \sigma^{2})")
\\ \omega \sim unif(0,1)\\")




![f(t) \sim N(b_{1} - b_{2}1_{\left[ \tau_{1},\tau_{2} \right]}(t), \sigma^{2})](http://s0.wp.com/latex.php?latex=f%28t%29+%5Csim+N%28b_%7B1%7D+-+b_%7B2%7D1_%7B%5Cleft%5B+%5Ctau_%7B1%7D%2C%5Ctau_%7B2%7D+%5Cright%5D%7D%28t%29%2C+%5Csigma%5E%7B2%7D%29++&bg=ffffff&fg=000&s=0 "f(t) \sim N(b_{1} - b_{2}1_{\left[ \tau_{1},\tau_{2} \right]}(t), \sigma^{2})")







}g(x)dx,")
![\int \frac{e^{-\frac{1}{2}x^{2}}}{g(x)}g(x)dx=\mathbb{E}\left[\frac{e^{-\frac{1}{2}x^{2}}}{g(x)} \right],](http://s0.wp.com/latex.php?latex=%5Cint+%5Cfrac%7Be%5E%7B-%5Cfrac%7B1%7D%7B2%7Dx%5E%7B2%7D%7D%7D%7Bg%28x%29%7Dg%28x%29dx%3D%5Cmathbb%7BE%7D%5Cleft%5B%5Cfrac%7Be%5E%7B-%5Cfrac%7B1%7D%7B2%7Dx%5E%7B2%7D%7D%7D%7Bg%28x%29%7D+%5Cright%5D%2C++&bg=ffffff&fg=000&s=0 "\int \frac{e^{-\frac{1}{2}x^{2}}}{g(x)}g(x)dx=\mathbb{E}\left[\frac{e^{-\frac{1}{2}x^{2}}}{g(x)} \right],")
![\mathbb{E}\left[\frac{e^{-\frac{1}{2}x^{2}}}{g(x)} \right] \approx \frac{1}{n}\sum_{i=1}^{n} \frac{e^{-\frac{1}{2}x_{i}^{2}}}{g(x_{i})},](http://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Cleft%5B%5Cfrac%7Be%5E%7B-%5Cfrac%7B1%7D%7B2%7Dx%5E%7B2%7D%7D%7D%7Bg%28x%29%7D+%5Cright%5D+%5Capprox+%5Cfrac%7B1%7D%7Bn%7D%5Csum_%7Bi%3D1%7D%5E%7Bn%7D+%5Cfrac%7Be%5E%7B-%5Cfrac%7B1%7D%7B2%7Dx_%7Bi%7D%5E%7B2%7D%7D%7D%7Bg%28x_%7Bi%7D%29%7D%2C++&bg=ffffff&fg=000&s=0 "\mathbb{E}\left[\frac{e^{-\frac{1}{2}x^{2}}}{g(x)} \right] \approx \frac{1}{n}\sum_{i=1}^{n} \frac{e^{-\frac{1}{2}x_{i}^{2}}}{g(x_{i})},")
") .
.